消息队列服务Kafka揭秘 痛点、优势与适用场景下的信息集成利器
在当今数据驱动的时代,企业面临着海量、高速、多样化的数据流挑战。如何高效、可靠地集成与处理这些信息流,成为技术架构的核心议题。Apache Kafka作为一款开源的分布式消息队列与流处理平台,凭借其独特的设计,已成为现代信息集成服务的基石。本文将深入揭秘Kafka,解析其应对的传统痛点、核心优势以及典型适用场景。
一、Kafka旨在解决的传统痛点
在Kafka等现代消息中间件出现之前,企业信息集成常面临以下困境:
- 系统紧耦合与单点故障:系统间常通过直接API调用或共享数据库集成,导致耦合度高。一个系统的故障或性能瓶颈极易引发链式反应,且数据库往往成为性能和可靠性的单点瓶颈。
- 数据吞吐与实时性瓶颈:传统消息队列(如ActiveMQ, RabbitMQ)在应对每秒数百万条消息的超高吞吐场景时,性能和扩展性面临挑战,难以满足实时数据流处理的需求。
- 数据丢失与可靠性风险:早期方案难以保证在系统故障、网络波动等情况下数据的零丢失与可靠传递。
- 历史数据回溯困难:大多数消息系统在消息被消费后即删除,无法为后续的数据重算、审计或新业务上线提供历史数据支持。
二、Kafka的核心优势
Kafka通过其分布式、持久化、高吞吐的架构设计,有效解决了上述痛点,形成了显著优势:
- 高吞吐与低延迟:采用顺序I/O、零拷贝、批量发送与压缩等技术,即使在普通硬件上也能支持每秒百万级的消息处理,延迟可低至毫秒级。
- 持久化与高可靠:所有消息均持久化到磁盘,并支持多副本冗余(Replication)。数据可配置保留长时间(如数天甚至数年),提供了“发布-订阅”和“消息回溯”的双重能力,数据可靠性极高。
- 高可扩展性:集群可轻松水平扩展,通过增加节点(Broker)来线性提升吞吐量和存储容量。主题(Topic)可以划分为多个分区(Partition),分布在不同节点上,实现并行处理。
- 流处理生态集成:不仅是消息队列,更是流处理平台。与Kafka Streams、KSQL、Flink、Spark Streaming等流处理框架深度集成,支持在数据流上进行复杂的实时计算与分析。
- 解耦与弹性:生产者与消费者完全解耦,互不知晓对方的存在。系统可以独立扩展、升级或故障,不会直接影响其他部分,提升了整体架构的弹性与容错能力。
三、Kafka在信息集成中的典型适用场景
基于其优势,Kafka在现代信息集成与服务架构中扮演着“中枢神经系统”的角色,主要适用于:
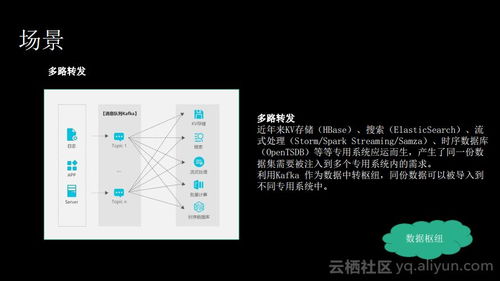
- 实时数据管道与日志聚合:这是Kafka最经典的场景。收集分布式服务(如微服务)产生的应用日志、用户行为日志、指标数据等,统一汇入Kafka,再实时流转到监控系统、数据仓库(如Hadoop, Hive)或搜索引擎(如Elasticsearch)中进行处理与分析。
- 事件驱动架构(EDA)的核心总线:在微服务或复杂系统架构中,Kafka作为事件总线,服务通过发布/订阅事件进行异步通信。例如,订单服务生成一个“订单创建”事件,库存服务、支付服务、物流服务分别订阅并处理,实现业务逻辑的解耦与异步化。
- 网站活动追踪:实时追踪用户在网站或APP上的每一次点击、浏览、搜索、购买等行为,以高吞吐的方式发送到Kafka,用于实时个性化推荐、广告投放、用户行为分析等。
- 运营指标监控:将各类服务器、应用、网络的性能指标(Metrics)持续写入Kafka,由下游的流处理应用进行实时聚合、告警,或存入时序数据库(如InfluxDB)供可视化展示。
- 流式ETL与数据同步:实现不同数据系统(如MySQL到Elasticsearch,Oracle到HDFS)之间的实时数据同步与转换,构建低延迟的数据湖或数据仓库的实时入湖通道。
###
Apache Kafka已从一个高性能的消息队列,演进为构建实时流数据管道和关键任务型应用程序的完整生态系统。它直面传统信息集成的痛点,以高吞吐、持久化、可扩展和流式处理为核心优势,成为连接数据生产者与消费者、支撑实时业务决策的不可或缺的“信息高速公路”。在选择Kafka时,也需考量其运维复杂性、对消息顺序和“恰好一次”语义的精确理解等因素。在需要处理大规模、实时数据流的现代信息集成场景中,Kafka无疑是首选的强力工具之一。
如若转载,请注明出处:http://www.njjhm.com/product/14.html
更新时间:2026-04-24 14:02:29